nodejs 공부 2024.06.14

간단한 게시판과 데이터베이스 연산
게시판 시스템을 통해 CRUD 기본 연산과 데이터베이스 설계의 중요성을 이해하며, 데이터를 효과적으로 관리하는 방법을 배울 수 있다. 이 시스템은 백엔드 및 임베디드 시스템 개발에 있어 필수적인 요소다.
CRUD 연산
생성(Create)
- 데이터베이스에 새로운 데이터를 삽입하는 작업이다.
읽기(Read)
- 저장된 데이터를 조회하는 작업으로, 조인을 활용해 여러 테이블의 데이터를 결합할 수 있다.
갱신(Update)
- 기존 데이터를 수정하는 연산이다.
삭제(Delete)
- 데이터를 제거하는 과정이며, 데이터 무결성을 유지하는 것이 중요하다.
데이터베이스 정규화
데이터베이스 설계 시 중복을 최소화하고 무결성을 높이기 위해 정규화 과정을 거친다. 정규화는 여러 단계로 나뉜다:
제1정규형(1NF)
- 각 컬럼에 원자값만이 들어가야 하며, 중복된 값이 없어야 한다.
제2정규형(2NF)
- 모든 비키 속성이 기본 키에 완전 함수적 종속을 만족해야 한다.
제3정규형(3NF)
- 이행적 종속을 제거하여 데이터 중복을 더욱 줄인다.
보이스/코드 정규형(BCNF)
- 기본 키가 아닌 모든 후보 키에 대해서도 종속성을 제거한다.
트랜잭션과 ACID 속성
트랜잭션은 데이터베이스의 안정성을 보장하기 위해 필수적인 작업 단위다. 트랜잭션은 ACID 속성에 의해 관리된다:
원자성(Atomicity)
- 트랜잭션 내의 모든 작업이 완전히 수행되거나 전혀 수행되지 않아야 한다.
일관성(Consistency)
- 트랜잭션은 일관된 데이터베이스 상태를 유지해야 한다.
고립성(Isolation)
- 동시에 실행되는 트랜잭션이 서로 영향을 주지 않아야 한다.
지속성(Durability)
- 성공적으로 수행된 트랜잭션은 시스템 오류가 발생해도 데이터베이스에 영구적으로 반영되어야 한다.
데이터 타입과 크기 지정
데이터의 크기와 타입을 올바르게 지정하는 것은 시스템의 효율성을 높이는 중요한 요소다:
- tinyint, smallint, int, bigint: 각 데이터 타입은 저장할 수 있는 값의 범위와 메모리 크기가 다르므로 용도에 맞게 선택해야 한다.
**<크기비교>**
tinyint < smallint < int < bigint
#tinyint
크기 : 0 ~ 255
비고 : 0을 시작으로 2^8(=2의8승=256)번째까지 정수
용량 : 1바이트
#smallint
크기 : -32,768 ~ 32,767
비고 : -2^15 ~ (2^15 - 1) 사이의 정수. 2의15승에서 1을 빼는 이유는 0의 자리가 포함되기 때문. 나머지들도 모두 마찬가지.
용량 : 2바이트
#int
크기 : -2,147,483,648 ~ 2,147,483,647
비고 : -2^31 ~ (2^31 - 1) 사이의 정수. 역시 0의 자리를 위해 양수에서 -1 해줌.
용량 : 4바이트
#bigint
크기 : -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,8087
비고 : -2^63 ~ (2^63 - 1) 사이의 정수. 0의 자리를 확보하기 위해 역시 뒤에서 -1 해줌.
용량 : 8바이트
데이터베이스 설계 최적화
적절한 테이블 생성과 데이터 무결성 유지는 효율적인 데이터베이스 시스템을 위해 필수적이다. 사용하지 않는 테이블은 제거하고, 데이터의 중복을 방지하는 설계를 통해 시스템의 성능을 최적화한다.
설계원칙
1. 단일 책임 원칙 (Single Responsiblity Principle) : srp
모든 클래스는 각각 하나의 책임만 가져야 한다. 클래스는 그 책임을 완전히 캡슐화해야 함을 말한다.
- 사칙연산 함수를 가지고 있는 계산 클래스가 있다고 치자. 이 상태의 계산 클래스는 오직 사칙연산 기능만을 책임진다. 이 클래스를 수정한다고 한다면 그 이유는 사직연산 함수와 관련된 문제일 뿐이다.
2. 개방-폐쇄 원칙 (Open Closed Principle) : ocp
확장에는 열려있고 수정에는 닫혀있는. 기존의 코드를 변경하지 않으면서( Closed), 기능을 추가할 수 있도록(Open) 설계가 되어야 한다는 원칙을 말한다.
- 캐릭터를 하나 생성한다고 할때, 각각의 캐릭터가 움직임이 다를 경우 움직임의 패턴 구현을 하위 클래스에 맡긴다면 캐릭터 클래스의 수정은 필요가없고(Closed) 움직임의 패턴만 재정의 하면 된다.(Open)
3. 리스코프 치환 원칙 (Liskov Substitution Principle) : lsp
자식 클래스는 언제나 자신의 부모 클래스를 대체할 수 있다는 원칙이다. 즉 부모 클래스가 들어갈 자리에 자식 클래스를 넣어도 계획대로 잘 작동해야 한다.
자식클래스는 부모 클래스의 책임을 무시하거나 재정의하지 않고 확장만 수행하도록 해야 LSP를 만족한다.
4. 인터페이스 분리 원칙 (Interface Segregation Principle) : isp
한 클래스는 자신이 사용하지않는 인터페이스는 구현하지 말아야 한다. 하나의 일반적인 인터페이스보다 여러개의 구체적인 인터페이스가 낫다.
5. 의존 역전 원칙 (Dependency Inversion Principle) : dip
의존 관계를 맺을 때 변화하기 쉬운 것 또는 자주 변화하는 것보다는 변화하기 어려운 것, 거의 변화가 없는 것에 의존하라는 것이다. 한마디로 구체적인 클래스보다 인터페이스나 추상 클래스와 관계를 맺으라는 것이다.
웹 수업시 들은 팁들
id가 블로그 url에 들어있는데 보안상 좋지 못하다고 해서 네이버에는 로그인시 블로그 주소를 1회에 한해서 바꿀 수 있다. 파워블로거나 그런사람들은 url을 바꾸면 안되기 때문에 (이전 주소 -> 새로운 주소 연결 지원3개월) 그리고 조회 수가 현저히 낮아질 수 있음
db 설계시 나중에 못바꾸게 될 수도 있기 때문에 최대한 생각을 많이 해서 설계하고 구현해야함.
autocommit을 풀지말아야함. 이유는 autocommit 설정이 false 이기 때문에 쿼리 종료시점에 수동으로 COMMIT 이 실행되어야함. 개발자가 명시적으로 실행하거나, @Transactional 을 사용할 수도 있음. @Transactional 은 메서드 종료 시점에 정상 종료 시 COMMIT, 예외 발생 시 ROLLBACK 을 실행키는데. COMMIT 이 실행되지 않으면, Consistent Nonlocking Reads 로 인해 Snapshot 이 갱신되지 않아 최초 쿼리 실행 시점 이후에 실행된 트랜잭션의 변경사항을 보지 못함.
외래키를 지정해도 되는데 이렇게 빡빡하게 묶어두면 게시글도, 유저삭제도, 관리가 빡빡해짐. 테이블을 진짜 지우기 보다 상태를 바꾸는 컬럼을 두고 0이면 삭제된거 1이면 활성화된거로 두면 됨 유저가 탈퇴해도 그 정보를 몇년간 보관이 필요하기 때문
쿼리가 익숙하지 않다면 아무 데이터나 워크벤치에 넣고 apply하면 쿼리 짜주는데 그걸 복사해서 사용하고 취소하기.
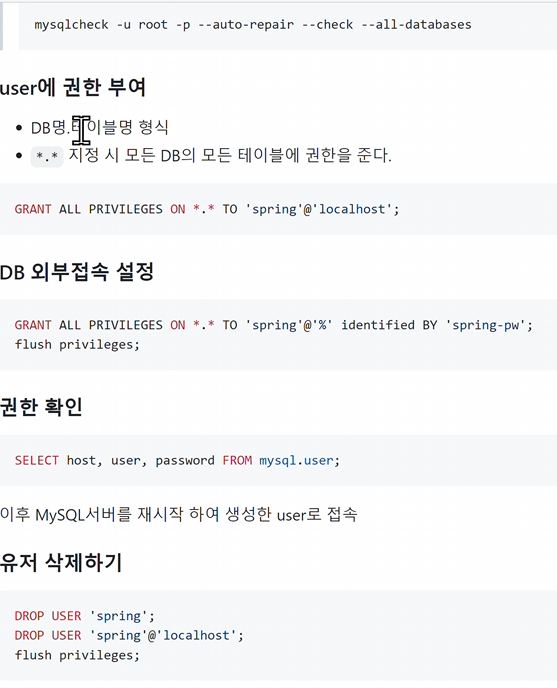
유저 권한 주기

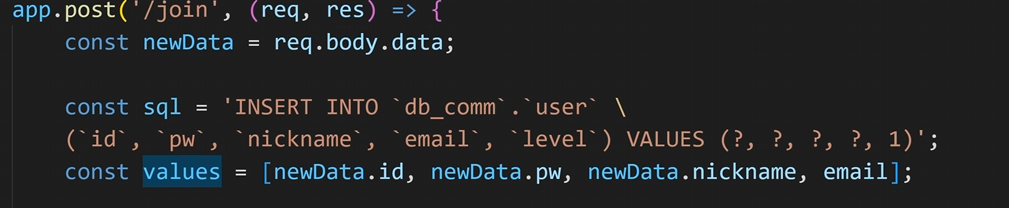
쿼리가 길면 사진과 같이 \ 백슬래시로 연결해줄 수 있음