자료구조 공부 2024.05.09
이진검색알고리즘
while문
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
# 이진 검색 알고리즘은 정렬된 리스트에서 특정한 값의 위치를 찾아내는 알고리즘입니다. BSearch_list = [7, 10, 12, 25, 27, 96, 1004] # 정렬된 리스트 search = 12 # 찾고자 하는 값 low = 0 # 검색 범위의 시작 인덱스 high = 6 # 검색 범위의 끝 인덱스 count = 0 # 비교 횟수 # low가 high보다 작거나 같을 때까지 반복합니다. while low <= high: middle = int((low + high) / 2) # 중간 인덱스 계산 # 중간 위치의 값과 찾는 값이 같은 경우 if search == BSearch_list[middle]: count += 1 print(f"주어진 리스트에서 인덱스[{middle}] 위치의 값인 {search}을/를 총{count}번만에 검색 성공") print("탐색 종료") break # 중간 위치의 값보다 찾는 값이 큰 경우 elif search > BSearch_list[middle]: low = middle + 1 count += 1 # 중간 위치의 값보다 찾는 값이 작은 경우 else: high = middle - 1 count += 1
선택정렬알고리즘
- 첫번째
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
# 선택 정렬 1 # 초기 배열 상태를 출력합니다. arr = [40, 70, 60, 30, 10, 50] print(f"선택정렬 전 : {arr}") print("+" * 40) # 구분선 출력 # 선택 정렬 알고리즘을 시작합니다. # 배열의 길이 - 1만큼 반복합니다. 마지막 원소는 자동으로 정렬됩니다. for i in range(len(arr) - 1): min_idx = i # 현재 단계에서 최소값의 인덱스를 가정하고 시작합니다. # i+1부터 배열의 끝까지 반복하며 실제 최소값의 위치를 찾습니다. for j in range(min_idx + 1, len(arr)): if arr[j] < arr[min_idx]: # 현재 선F=택된 최소값보다 더 작은 값을 찾으면 min_idx = j # 최소값의 인덱스를 갱신합니다. # 현재 i 위치의 값과 찾은 최소값을 교환합니다. arr[i], arr[min_idx] = arr[min_idx], arr[i] # 각 단계의 결과를 출력합니다. print(f"{i + 1}단계: {arr}") print("+" * 40) # 구분선 출력 # 최종 정렬된 배열을 출력합니다. print(f"선택정렬 결과 : {arr}") # 코드 설명 # 선택 정렬 시작 전 배열 상태 출력: print(f"선택정렬 전 : {arr}")는 정렬 시작 전의 배열을 보여줍니다. # 구분선 출력: print("+" * 40)은 코드의 가독성을 높이기 위해 구분선을 출력합니다. # 바깥쪽 for 루프: for i in range(len(arr) - 1):는 0부터 배열 길이의 -1까지 반복하며, 이는 마지막 원소를 제외한 모든 원소에 대해 최소값을 찾아 정렬하는 과정을 의미합니다. # 최소값 가정: min_idx = i는 i번째 원소를 현재 최소값으로 가정합니다. # 안쪽 for 루프: for j in range(min_idx + 1, len(arr)):는 min_idx+1부터 배열의 끝까지 최소값을 찾는 과정을 수행합니다. # 최소값 갱신: if arr[j] < arr[min_idx]:는 현재 가정된 최소값보다 더 작은 값을 찾았을 때 최소값의 인덱스를 갱신합니다. # 값 교환: arr[i], arr[min_idx] = arr[min_idx], arr[i]는 현재 i 위치의 원소와 찾은 최소값의 원소를 교환합니다. # 각 단계 결과 출력: print(f"{i + 1}단계: {arr}")는 각 정렬 단계 후의 배열 상태를 출력합니다. # 최종 정렬 결과 출력: print(f"선택정렬 결과 : {arr}")는 완전히 정렬된 배열을 출력합니다.
- 두번째
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44
# 선택 정렬 2 def select_sort(arr): min_idx = 0 # 최소값의 인덱스를 저장할 변수 print(f"선택정렬 전 : {arr}") # 정렬 전 배열 상태 출력 # 배열의 길이 - 1만큼 반복 (마지막 원소는 자동으로 정렬됨) for i in range(len(arr)-1): min_idx = i # 현재 단계에서 i를 최소값의 인덱스로 초기화 print(f"인덱스[{min_idx}]의 값인 {arr[min_idx]}의 위치", end='->') # i+1부터 배열의 끝까지 반복하여 실제 최소값의 위치를 찾음 for j in range(min_idx + 1, len(arr)): if arr[j] < arr[min_idx]: # 더 작은 값이 발견되면 min_idx = j # 최소값의 인덱스를 갱신 # 현재 i 위치의 값과 찾은 최소값의 위치에 있는 값을 교환 arr[i], arr[min_idx] = arr[min_idx], arr[i] # 각 단계에서의 배열 상태와 교환 정보를 출력 print(f"배열에서 가장 작은 값인 {arr[i]} 위치[{min_idx}]와 변경") print(f"인덱스[{i}] 단계 교환 후 결과 : {arr}") print() # 정렬 완료 후의 배열 상태를 출력 print("="*70) print(f"선택 정렬된 이후 : {arr}") # 예제 배열 arr = [40, 70, 60, 30, 10, 50] select_sort(arr) # 코드 설명 # 함수 정의: def select_sort(arr): 선택 정렬을 수행하는 함수를 정의합니다. # 초기 최소값 인덱스 설정: min_idx = 0 초기에 최소값의 인덱스를 0으로 설정합니다. # 정렬 전 배열 상태 출력: print(f"선택정렬 전 : {arr}") 정렬하기 전의 배열 상태를 출력합니다. # 바깥쪽 for 루프: for i in range(len(arr)-1): 배열의 길이 - 1 만큼 반복합니다. 마지막 원소는 자동으로 정렬됩니다. # 최소값 인덱스 재설정: min_idx = i 각 단계마다 i를 최소값의 인덱스로 초기화합니다. # 탐색 범위 및 시작 상태 출력: print(f"인덱스[{min_idx}]의 값인 {arr[min_idx]}의 위치", end='->') 현재 단계에서 시작하는 인덱스와 값을 출력합니다. # 안쪽 for 루프: for j in range(min_idx + 1, len(arr)): 현재 인덱스 + 1부터 배열 끝까지 최소값을 탐색합니다. # 최소값 갱신: if arr[j] < arr[min_idx]: 현재 값이 최소값보다 작으면 최소값 인덱스를 갱신합니다. # 값 교환 및 교환 결과 출력: arr[i], arr[min_idx] = arr[min_idx], arr[i] 현재 위치의 값과 최소값을 교환하고, 교환된 결과를 출력합니다. # 단계별 결과 출력: print(f"인덱스[{i}] 단계 교환 후 결과 : {arr}") 각 단계에서 교환 후의 배열 상태를 출력합니다. # 최종 결과 출력: print("="*70) 구분선을 출력한 후, print(f"선택 정레된 이후 : {arr}") 최종 정렬된 배열 상태를 출력합니다
버블정렬알고리즘
- 첫번째
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
# 버블 정렬 1 #알고리즘을 이용하여 배열을 오름차순으로 정렬하는 예제 # 초기 배열 상태를 출력합니다. arr = ["다", "나", "마", "가", "사", "바", "라"] print(f"정렬 전: {arr}") print("=" * 50) # 구분선 출력 # 버블 정렬 알고리즘 시작 # 배열의 길이 - 1부터 1까지 역순으로 반복합니다. for i in range(len(arr)-1, 0, -1): # 0부터 i까지 반복하며 인접한 원소를 비교하고 필요에 따라 교환합니다. for j in range(i): if arr[j] > arr[j+1]: # 현재 원소가 다음 원소보다 크면 arr[j], arr[j+1] = arr[j+1], arr[j] # 두 원소의 위치를 교환 print(f"리스트에서 서로 이웃한 현재 값 중 작은 값인 '{arr[j]}'의 인덱스[{j+1}]의 위치를 변경하면") print(f"[단계별 교환 후 정렬 과정 : {arr}") else: print(f"[단계별 교환 후 정렬 과정 : [{arr[j]}]와 {[arr[j+1]]}의 값 크기가 변동없음") print() print("=" * 50) # 구분선 출력 print(f"정렬 후 : {arr}") # 정렬된 배열을 출력 # 코드 설명 # 함수 정의: def bubble_sort(arr): 버블 정렬을 수행하는 함수를 정의합니다. # 정렬 전 배열 상태 출력: print(f"정렬 전: {arr}") 정렬 시작 전의 배열 상태를 출력합니다. # 구분선 출력: print("=" * 50)은 코드의 가독성을 높이기 위해 구분선을 출력합니다. # 바깥쪽 for 루프: for i in range(len(arr)-1, 0, -1): 배열의 길이 - 1부터 1까지 역순으로 반복합니다. 이는 각 단계에서 정렬이 필요한 마지막 인덱스를 지정합니다. # 안쪽 for 루프: for j in range(i): 0부터 i까지 반복하며 인접한 두 원소를 비교합니다. # 원소 비교 및 교환: # if arr[j] > arr[j+1]: 현재 원소가 다음 원소보다 크면 두 원소의 위치를 교환합니다. # arr[j], arr[j+1] = arr[j+1], arr[j] 위치 교환을 실행합니다. # 교환 후 배열 상태를 출력합니다: print(f"리스트에서 서로 이웃한 현재 값 중 작은 값인 '{arr[j]}'의 인덱스[{j+1}]의 위치를 변경하면")와 print(f"[단계별 교환 후 정렬 과정 : {arr}"). # 교환 없을 때의 출력: # else: 교환하지 않고, 현재 상태를 출력합니다. # print(f"[단계별 교환 후 정렬 과정 : [{arr[j]}]와 {[arr[j+1]]}의 값 크기가 변동없음"). # 최종 결과 출력: print("=" * 50) 구분선을 출력한 후, print(f"정레 후 : {arr}") 최종 정렬된 배열 상태를 출력합니다.
- 두번째
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
# 버블 정렬 2 import random # 버블 정렬 알고리즘을 구현한 함수 def bubble(arr): # 배열의 길이 - 1부터 1까지 역순으로 반복 for i in range(len(arr)-1, 0, -1): # 0부터 i까지 반복하며 인접한 원소를 비교하고 필요에 따라 교환 for j in range(i): if arr[j] > arr[j+1]: # 현재 원소가 다음 원소보다 크면 arr[j], arr[j+1] = arr[j+1], arr[j] # 두 원소의 위치를 교환 print(f"리스트에서 서로 이웃한 현재 값 중 작은 값인 '{arr[j]}'의 인덱스[{j+1}] 위치를 변경하면") print(f"[단계별 교환 후 정렬 과정 : {arr}") else: print(f"[단계별 교환 후 정렬 과정 : [{arr[j]}]와 {[arr[j+1]]}의 값 크기가 변동없음") print() print("=" * 50) # 구분선 출력 print(f"정렬 후 : {arr}") # 정렬된 배열을 출력 # random.sample 함수를 이용해 1부터 100까지의 수 중 무작위로 6개를 추출하여 배열 생성 arr1 = random.sample(range(1, 101), 6) print(f"정렬 전 : {arr1}") # 정렬 전 배열 상태 출력 print("=" * 50) # 구분선 출력 bubble(arr1) # 버블 정렬 함수 호출 # 코드 설명 # 모듈 임포트: import random는 난수 생성을 위해 random 모듈을 임포트합니다. # 버블 정렬 함수 정의: def bubble(arr): 버블 정렬을 수행하는 함수를 정의합니다. # 바깥쪽 for 루프: for i in range(len(arr)-1, 0, -1): 배열의 길이 - 1부터 1까지 역순으로 반복합니다. 각 단계에서 정렬이 필요한 마지막 인덱스를 지정합니다. # 안쪽 for 루프: for j in range(i): 0부터 i까지 반복하며 인접한 두 원소를 비교합니다. # 원소 비교 및 교환: # if arr[j] > arr[j+1]: 현재 원소가 다음 원소보다 크면 두 원소의 위7 치를 교환합니다. # arr[j], arr[j+1] = arr[j+1], arr[j] 위치 교환을 실행합니다. # 교환 후 배열 상태를 출력합니다: print(f"리스트에서 서로 이웃한 현재 값 중 작은 값인 '{arr[j]}'의 인덱스[{j+1}] 위치를 변경하면")와 print(f"[단계별 교환 후 정렬 과정 : {arr}"). # 교환 없을 때의 출력: # else: 교환하지 않고, 현재 상태를 출력합니다. # print(f"[단계별 교환 후 정렬 과정 : [{arr[j]}]와 {[arr[j+1]]}의 값 크기가 변동없음"). # 최종 결과 출력: print("=" * 50) 구분선을 출력한 후, print(f"정렬 후 : {arr}") 최종 정렬된 배열 상태를 출력합니다. # 배열 생성 및 정렬 전 상태 출력: # arr1 = random.sample(range(1, 101), 6)는 1부터 100까지의 수 중 무작위로 6개를 추출하여 arr1 배열을 생성합니다. # print(f"정렬 전 : {arr1}") 정렬 전 배열 상태를 출력합니다. # print("=" * 50) 구분선을 출력합니다. # bubble(arr1) 버블 정레 함수를 호출하여 배열을 정렬합니다.
연결리스트
나
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
class Node:
def __init__(self, data):
self.data = data # 노드가 저장할 데이터
self.next = None # 다음 노드를 가리키는 포인터
class LinkedList:
def __init__(self):
self.head = None # 처음에는 빈 리스트이므로 head는 None입니다.
def append(self, data):
new_node = Node(data) # 새 데이터를 가진 노드 생성
if not self.head: # 리스트가 비어있다면
self.head = new_node # 새 노드를 head로 설정
return
last_node = self.head
while last_node.next: # 마지막 노드를 찾을 때까지 반복
last_node = last_node.next
last_node.next = new_node # 마지막 노드의 next를 새 노드로 설정
def display(self):
current = self.head
while current:
next_data = current.next.data if current.next else "None"
print(f"value: {current.data}, next: {next_data}")
current = current.next
# def display(self):
# current = self.head
# while current:
# print("value: "+current.data) # 현재 노드의 데이터 출력
# current = current.next # 다음 노드로 이동
# print("final node") # 줄 바꿈
# 연결 리스트 생성
linked_list = LinkedList()
# 데이터 추가
linked_list.append("일")
linked_list.append("수")
linked_list.append("목")
linked_list.append("월")
linked_list.append("화")
linked_list.append("금")
linked_list.append("토")
# 리스트 출력
linked_list.display() # 출력
답지
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
a={'head':['일',65], 65:['월',54], 54:['화',12], 12:['수',117], 117:['목',80], 80:['금',31], 31:['토', None]}
#현재 데이터가 다음 데이터 주소를 함께 정의
a["head"][0]="일"
a["head"][1]=65 #다음 데이터 키
a[65][0]="월"
a[65][1]=54 #다음 데이터 키
a[54][0]="화"
a[54][1]=12 #다음 데이터 키
a[12][0]="수"
a[12][1]=117 #다음 데이터 키
a[117][0]="목"
a[117][1]=80 #다음 데이터 키
a[80][0]="금"
a[80][1]=31 #다음 데이터 키
a[31][0]="토"
a[31][1]=None #다음 데이터 키
# 노드 순회
def test1(a,root_key):
head=root_key
node_next=head
print("node next",node_next)
while True:
node_value = a[node_next][0]
node_next = a[node_next][1]
print('value:',node_value)
if node_next == None:
print('final node ')
break
print("="*30)
def test2(a,root_key):
head=root_key
node_next=head
print("head(시작):", node_next)
while node_next != None:
node_value = a[node_next][0]
node_next = a[node_next][1]
print('value:',node_value)
print('next addr:', node_next)
#test1(a,"head")
test2(a,"head")
연결리스트 활용
1. 캐시 시스템
연결 리스트를 사용하여 캐시 시스템에서 데이터의 최근 사용 순서를 관리할 수 있음. 예를 들어, Least Recently Used (LRU) 캐시는 가장 오래된 항목을 캐시에서 제거해야 할 때 유용하게 사용. 각 항목에 대한 액세스가 발생할 때마다, 이 연결 리스트를 사용하여 항목의 순서를 빠르게 업데이트할 수 있다.
2. 실행 취소 기능
프로그램에서 실행 취소(undo) 기능을 구현할 때, 사용자의 각각의 액션을 노드로 저장하여 이전 상태로 쉽게 돌아갈 수 있도록 할 수 있다. 사용자가 실행 취소를 요청하면, 리스트를 거슬러 올라가 이전 상태를 복원함.
3. 인덱스가 필요 없는 데이터 구조
연결 리스트는 배열과는 달리 인덱스를 사용하지 않기 때문에, 중간에 데이터를 추가하거나 삭제할 때 다른 요소들을 이동하지 않아도 됨. 따라서 연속적인 메모리 할당이 어려운 환경에서 유용하게 사용될 수 있다.
4. 멀티레벨 트랜잭션 관리
데이터베이스 트랜잭션이나 멀티 스테이지 작업을 관리할 때, 각 단계의 결과를 노드에 저장하여 이전 단계로 쉽게 롤백할 수 있다.
5. 게임 개발
게임에서 캐릭터나 객체의 상태를 관리하는 데 사용될 수 있음. 예를 들면, 게임 내에서 특정 이벤트나 상태의 변화를 순차적으로 추적하고 관리할 때 유용함.
이런 방식의 연결 리스트는 기존의 객체지향적 연결 리스트보다 더 유연하고 직관적인 관리를 가능하게 해줄 수 있음. 그러나, 큰 데이터 집합에 대해서는 키-값 조회 성능이 중요할 수 있으므로, 성능 저하를 방지하기 위한 최적화가 필요할 수 있다.
활용 예시
1. LRU 캐시 구현
Least Recently Used (LRU) 캐시는 자주 사용되지 않는 데이터를 제거하여 효율적으로 메모리를 관리하는 방식. 파이썬의 사전과 연결 리스트를 조합하여 LRU 캐시를 구현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class Node:
def __init__(self, key, value):
self.key = key
self.value = value
self.prev = None
self.next = None
class LRUCache:
def __init__(self, capacity):
self.capacity = capacity
self.dictionary = {}
self.head, self.tail = Node(0, 0), Node(0, 0)
self.head.next = self.tail
self.tail.prev = self.head
def get(self, key):
if key in self.dictionary:
node = self.dictionary[key]
self._remove(node)
self._add(node)
return node.value
return -1
def put(self, key, value):
if key in self.dictionary:
self._remove(self.dictionary[key])
node = Node(key, value)
self._add(node)
self.dictionary[key] = node
if len(self.dictionary) > self.capacity:
node = self.head.next
self._remove(node)
del self.dictionary[node.key]
def _remove(self, node):
p, n = node.prev, node.next
p.next, n.prev = n, p
def _add(self, node):
p = self.tail.prev
p.next = node.next = self.tail
node.prev = p
self.tail.prev = node
이 코드는 연결 리스트와 해시 테이블을 결합하여 빠른 삽입과 삭제를 가능하게 하며, 가장 최근에 사용된 항목을 캐시의 뒷부분으로 이동시키고, 가장 오래된 항목을 제거한다.
2. 실행 취소 기능
텍스트 에디터에서 실행 취소 기능을 구현할 수 있는 방법
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class ActionNode:
def __init__(self, state):
self.state = state
self.prev = None
class UndoManager:
def __init__(self):
self.current = None
def save_state(self, state):
new_node = ActionNode(state)
new_node.prev = self.current
self.current = new_node
def undo(self):
if self.current is not None:
state = self.current.state
self.current = self.current.prev
return state
return None
사용자의 각 행동을 연결 리스트로 저장하고, 실행 취소 요청이 있을 때 이전 상태로 돌아갈 수 있다.
문제풀기
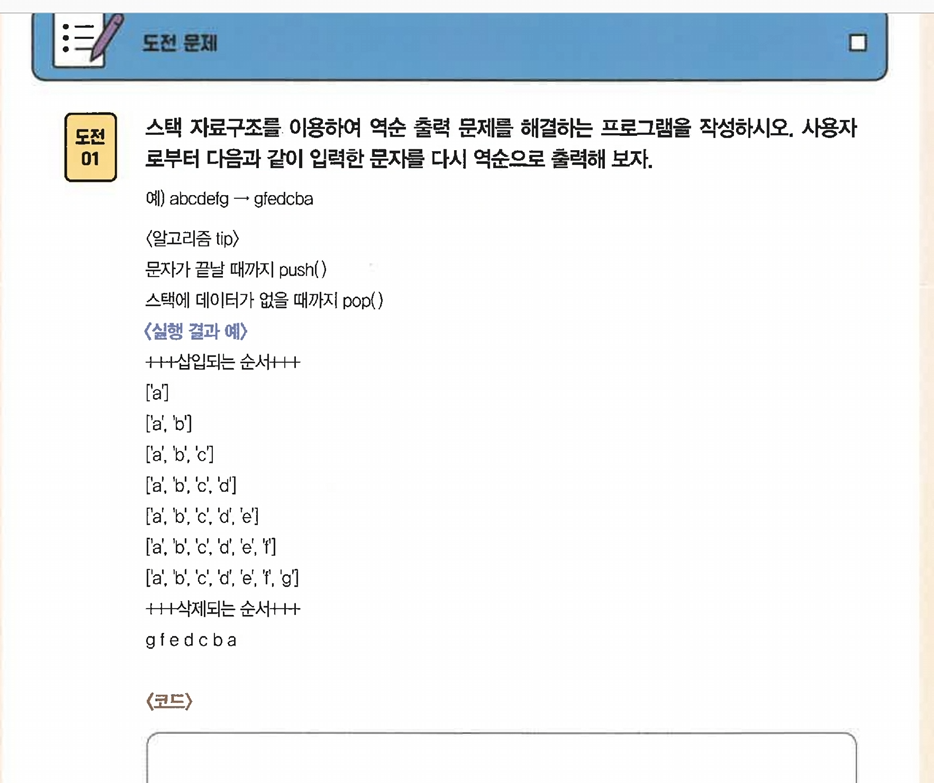
1
2
3
4
5
6
7
8
9
10
11
12
13
user_str = list(input("입력하셈 문자열: "))
dt = []
for i in range(1,len(user_str)+1):
print("++삽입되는 순서++")
print(f"{user_str[:i]}")
while user_str:
dt.append(user_str.pop())
print("---------------------")
print("++삭제되는순서++")
print(" ".join(dt))
